We’ll talk about CNN.
CNN is an architecture designed to handle images correctly and solve the problem of Fully Connected.
But what exactly is the problem of Fully Connected?
The problem is that images are made up of pixels, and the pixel size varies depending on whether they’re RGB, CMYK, etc. But the key isn’t the type; it’s the number of pixels and their spatial arrangement. When we take pixels and perform Fully Connected operations, the weights become enormous. For example, if an image is 3224224 = 150,528 features, and we assume the first layer of the Neural Network has 1000 neurons, that’s 150 million weights. Imagine the weights of the other layers! This leads to problems like massive calculations, overfitting, and a lack of spatial understanding. Plus, each pixel is processed independently. This is where CNNs come in.
CNNs were created to understand images like we do. Keep in mind that we humans don’t see the entire image at once; we see small details, and the brain assembles the image. CNNs attempt to mimic this by being able to see edges, then shapes, then objects—essentially, a gradual image view, much like how humans are viewed. This is called a local receptive field.
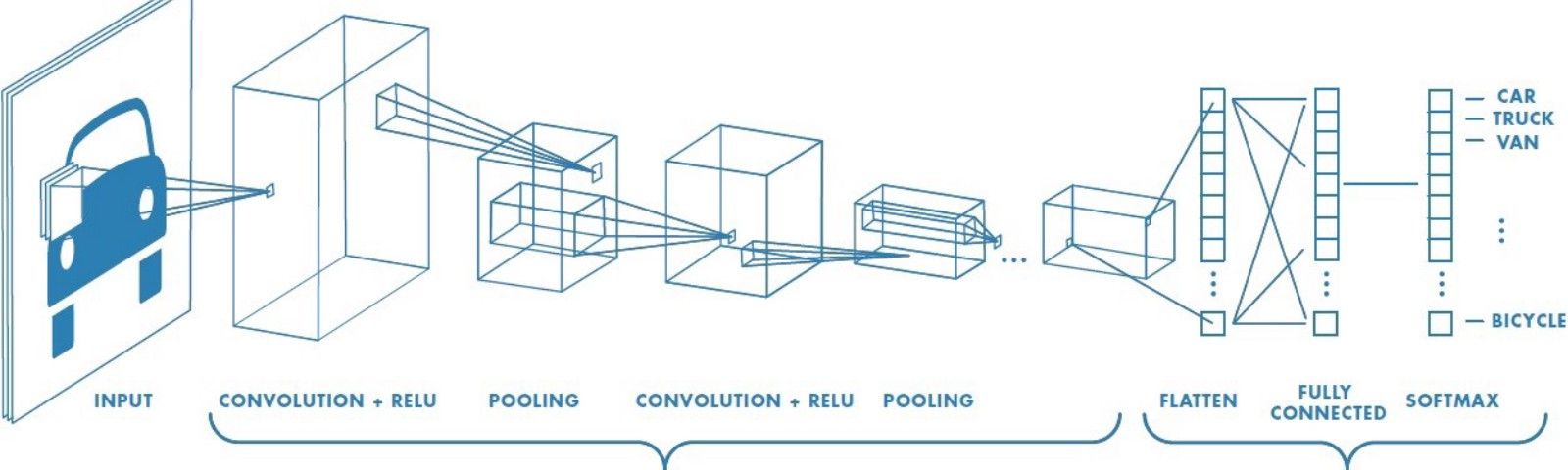
CNNs consist of three main layers: the convolutional layer, the pooling layer, and the fully connected layer.
The basic idea is to start by using a small filter called a kernel (e.g., 3x3 or 5x5). This filter is applied to the image and has the same depth as the image (e.g., 3x3x3 in RGB). It produces a single feature map. Then, the convolutional layer and its equation calculate the feature map: feature map = kernel * image. Note that the * doesn’t just mean multiplication; it’s a weighted sum + bias. This means multiplying the kernel by a portion of the image, adding, and repeating. Also, keep in mind that you can use one filter or multiple filters, each producing a different feature map. This is a feature we call the Parameter sharing involves using the same parameters as weights. The longer we use the filter, the more we use the same parameters, resulting in consistent weights across the entire image. Only the location changes.
This was an ingenious solution because the weights are small, the same filter is applied everywhere, and it understands patterns, not pixels.
Next, we implement Padding and Stride. Padding maintains image size, while Stride improves speed and size. Next, we apply Activation (ReLU). Without it, the model would be linear, and the relationship between pixels and labels is non-linear. Activation is essential, and ReLU also solves the vanishing gradient problem. Finally, we apply Max Pooling to reduce size while preserving key features. Pooling increases translation invariance, but this isn’t always necessary, as some modern architectures like ResNet minimize its use. Furthermore, the primary purpose of the Pooling Layer is to… Next, we move to the Flatten layer to convert feature maps to vectors, since neural networks deal with vectors. Then, in the Fully Connected Layers, we take the features, make a decision, use Softmax, calculate the probability, and choose the feature with the highest probability.
CNNs are powerful because they reduce overfitting problems and the number of weights. They also have the advantage of parameter sharing.
All of this was the forward process, but CNNs learn filters, and of course, there’s always a certain line. Therefore, they need to perform backpropagation and use an optimizer. This is because a CNN is essentially a regular neural network, but the key lies in the layers within it.